训练一个AI歌手且翻唱一首歌曲,共需要以下几步:
- 准备数据集
- 训练模型
- 模型推理
本文以训练AI优香为例,详细介绍从0开始如何训练得到一个AI歌手。不需要您了解原理,只需要跟随本文点点点即可得到模型。
使用到的项目地址为:
https://github.com/RVC-Boss/Retrieval-based-Voice-Conversion-WebUI
作者的B站首页:https://space.bilibili.com/5760446?spm_id_from=333.337.0.0
作者做的本项目的介绍:
https://www.bilibili.com/video/BV1pm4y1z7Gm/?spm_id_from=333.999.0.0
可以在B站私信作者下载该项目的整合包,本文使用的也是整合包(一键部署,省去很多麻烦)。
准备数据集
数据集的重要性
可以这么说,模型效果的上限取决于数据集。
数据集越好,即使训练模型的算法较差,最后训练得到的模型的效果也不会差到哪里去。业界中存在这样一个说法:“数据集决定了一个模型的上限,算法则无限逼近这个上限。”著名人工智能大师吴恩达也曾指出,机器学习任务中,数据和模型的占比为8:2。
从中可以看出,数据集对于模型来说是至关重要的。
数据集的要求
回归主题,我们要训练一个AI歌手,在这个业务场景下,音频是我们所需要的数据。数据可以是某个角色的语音、歌曲等,形式不限,但有一点至关重要:一定要保证角色语音干净清晰,不能含有背景音乐、杂音或者混响等。
数据集的获取
如果要训练的角色是一个歌手,可以挑选他(她)的不含和声的歌曲,通过分离人声和去除混响操作来获取干净的歌声。
如果要训练游戏/动漫/电影等中的角色,可以录制ta的语音,或者在网上寻找语音包(B站有很多)来获取ta的语音。
本文训练的角色为《碧蓝档案》中的早濑优香,因为在B站可以找到该角色的全语音包,且音频干净无杂音,所以直接使用全语音包作为数据集,链接如下:
https://www.bilibili.com/video/BV1mX4y167GM/?spm_id_from=333.337.search-card.all.click
数据集的处理
- 下载该项目的整合包。看好下载的版本,再下载一份对应版本的补丁。
- 在项目根目录下,双击go-web.bat,跳转到项目部署web页面(首次启动有些慢,耐心等待即可),页面如下:

注意,自此往后,直到模型推理结束,不要关闭cmd窗口(黑窗口)!!! - 如果您的语音中含有背景音乐、混响或者回声等,点击“伴奏人声分离&去混响&去回声”选项,将需要处理的音频文件拖至左下角的面板。然后根据需求选择对应的模型(音乐有和声,选择HP5,没有和声选择HP2或者HP3都行;去混响选择onnx_dereverb,去混响操作比较费时)。
因为优香的语音包没有音乐,也没有混响,所以本文没有对优香语音包进行处理。
训练模型
- 点击“训练”选项,填写实验配置。
页面如下:
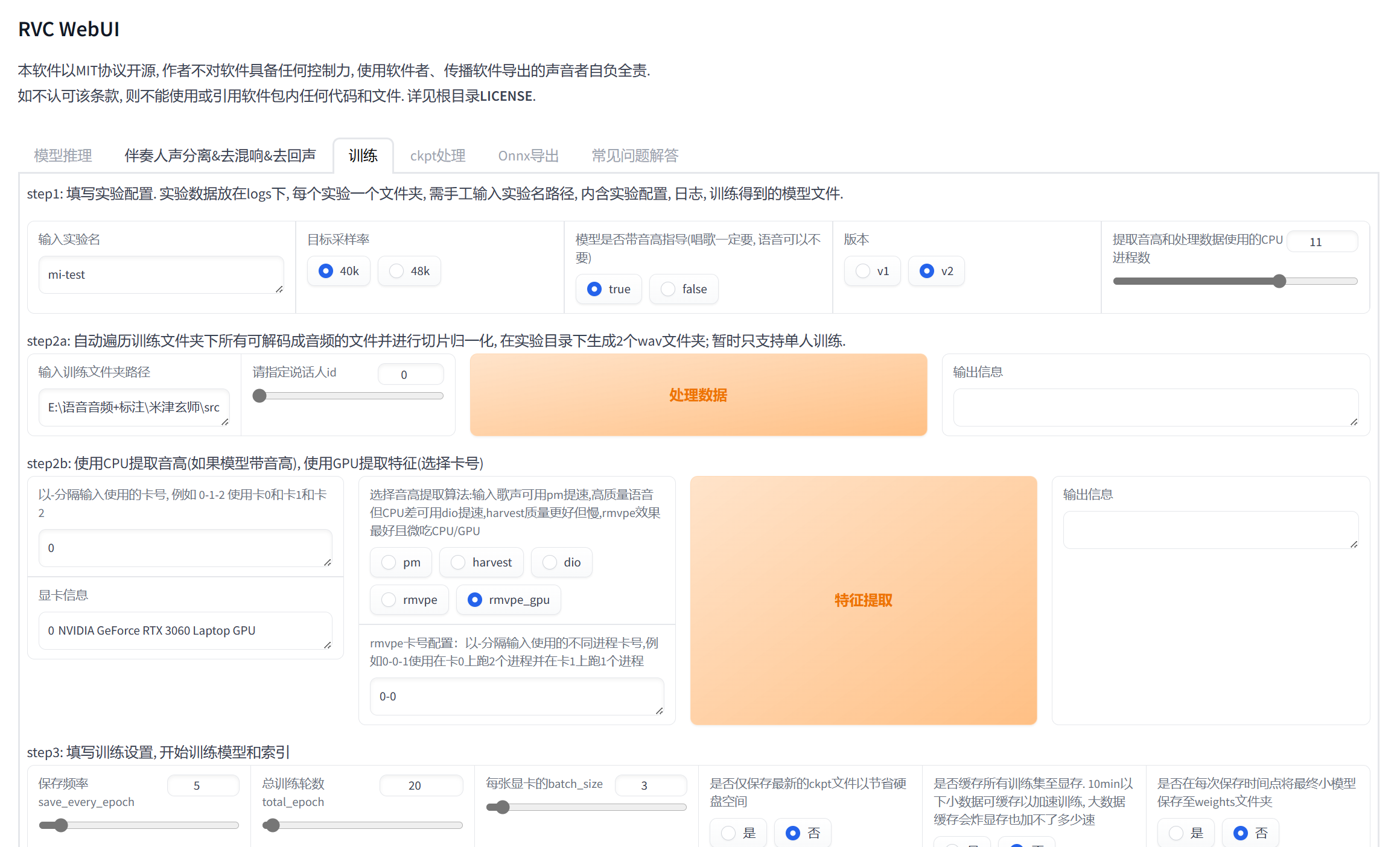
输入实验名,本文使用yuuka作为实验名。
目标采样率,说的是输入的音频的质量,40k采样质量没有48k质量高。
重点,如果训练得到的模型用以唱歌,一定要勾选true。
其他配置使用默认的即可。
本文的配置如下:

- 输入训练文件夹的路径,注意,路径不包含数据文件,路径为数据文件存放的文件夹的地址。
笔者的数据文件存放地址如下:

- 单击“处理数据”。出现如下提示代表数据处理完成:

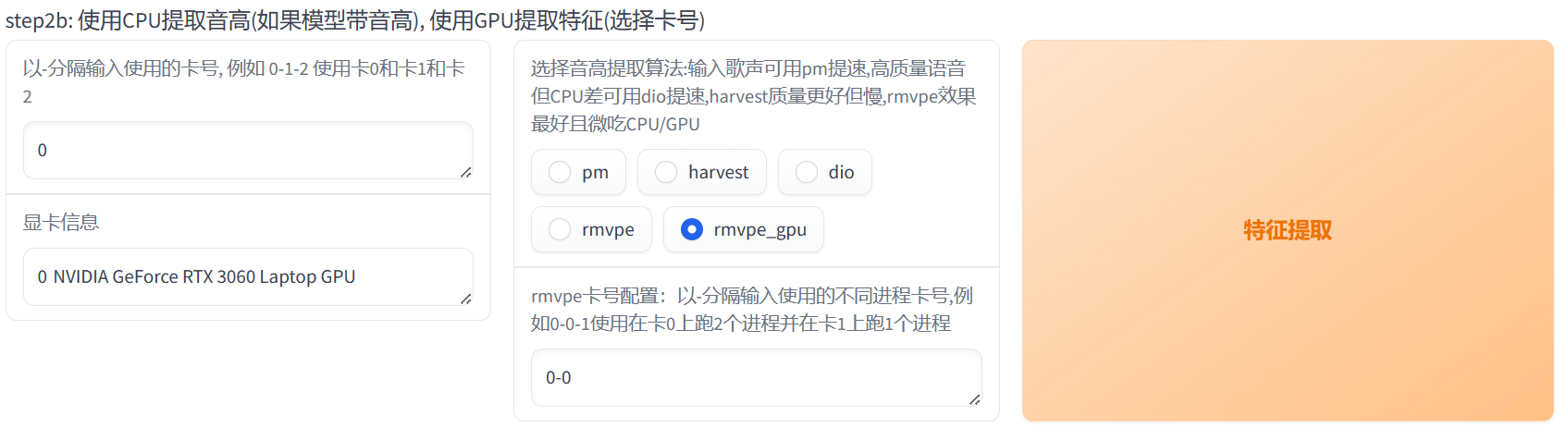
- 该页面能够自动识别电脑可用显卡,因为笔者电脑只有一张显卡,所以分配的卡号直接为0,如果包含多张卡,可以按照提示填写多张卡号。
选择音高提取算法,如果输入的是歌声,可以选择pm算法(速度比较快),输入其他数据依个人需求自行选择算法,笔者这里选择rmvpe_gpu算法。
笔者这部分配置如下:
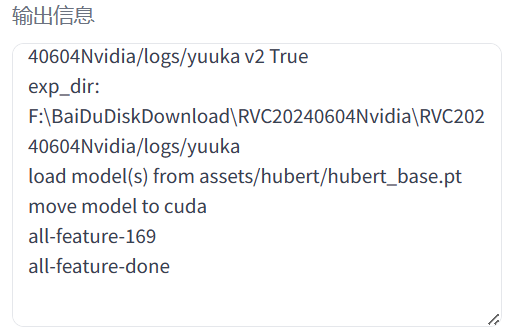
- 点击“特征提取”。出现“all-feature-done”代表特征提取完毕:
- 填写训练配置。
·保存频率为多少个epoch保存一下模型文件;
·总训练轮数为训练多少个epoch,一般来说,随着epoch的增加,模型的训练效果会先上升然后保持平稳,epoch越大,训练时间越久;
·batch_size为每轮梯度更新用到的数据个数,batch_size越大,对显存要求越高;
·可以选择是否仅保存最新的ckpt来节省硬盘;
其他的按照默认配置即可。不要动预训练底膜路径!
笔者这部分的配置如下:
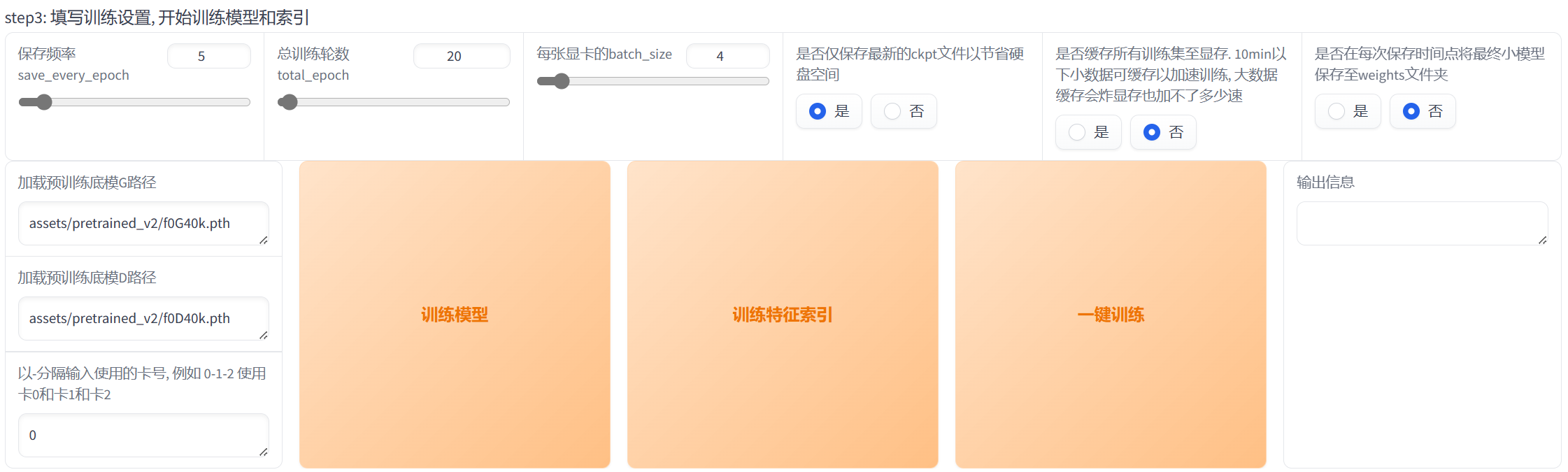
- 点击“一键训练”,等待训练完成即可,期间可以通过命令行窗口(cmd窗口/黑窗口)查看模型训练情况。

可以看到,笔者第一轮epoch训练用时大约三分钟。
我们也可以通过任务管理器来查看cpu和gpu的使用情况,笔者在训练过程的某一刻,gpu利用率如下:

可以看到,笔者的模型正在利用gpu进行训练,耐心等待模型训练完毕即可。
模型推理
- 点击“模型推理”选项,选择刚刚训练得到的模型。
因为笔者刚才的实验名称为yuuka,所以训练得到的模型名称为yuuka.pth,点击yuuka.pth。
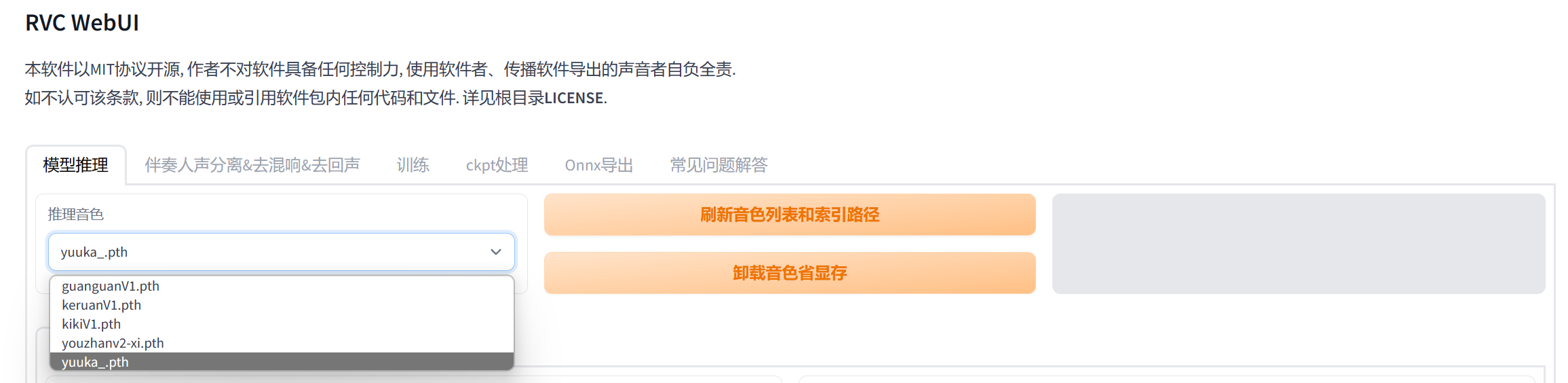
ps.如果没有看到刚刚训练得到的模型,点击刷新。如果还是没有看到,说明模型训练阶段出现了问题,没有得到.pth文件。请自行查询模型训练阶段出现的问题。 - 模型推理只能使用干净的人声,所以我们需要得到待翻唱歌曲的纯人声。可以重复上述数据集处理中的“伴奏人声分离&去混响&去回声”操作,这里不再赘述。另外,如果对该项目自带的人声分离效果不满意,可以使用第三方软件进行人声分离,例如:Audition、NovaMSS等软件,笔者当时使用的是NovaMSS软件,因为NovaMSS可以说是傻瓜式操作,点几下就可以分离出人声、伴奏。
- 得到纯人声后,输入该人声所在的地址,这个地址包含人声文件的名称,注意不要和前面的地址搞混,笔者的人声文件存放如下:
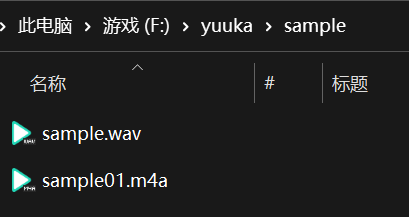
使用的文件是sample.wav,所以应该输入F:\yuuka\sample\sample.wav。 - 选择训练得到的特征索引。
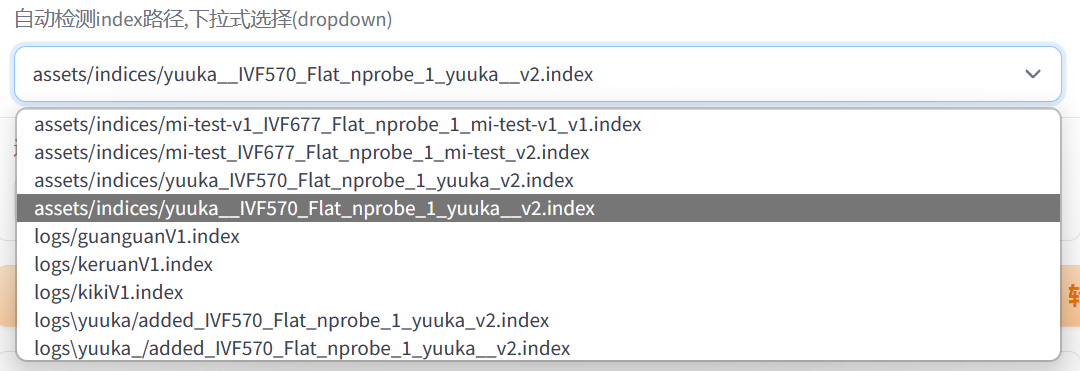
注意要选择实验名称对应的索引文件。 - 音高提取算法可以使用pm(速度较快)。笔者使用的是rmvpe算法,因为效果最好,但是稍微消耗一点gpu。
- 此时就可以点击“转换”来获得目标人声了。
- 我们可以根据目标人声效果的好坏来更改如下推理属性:
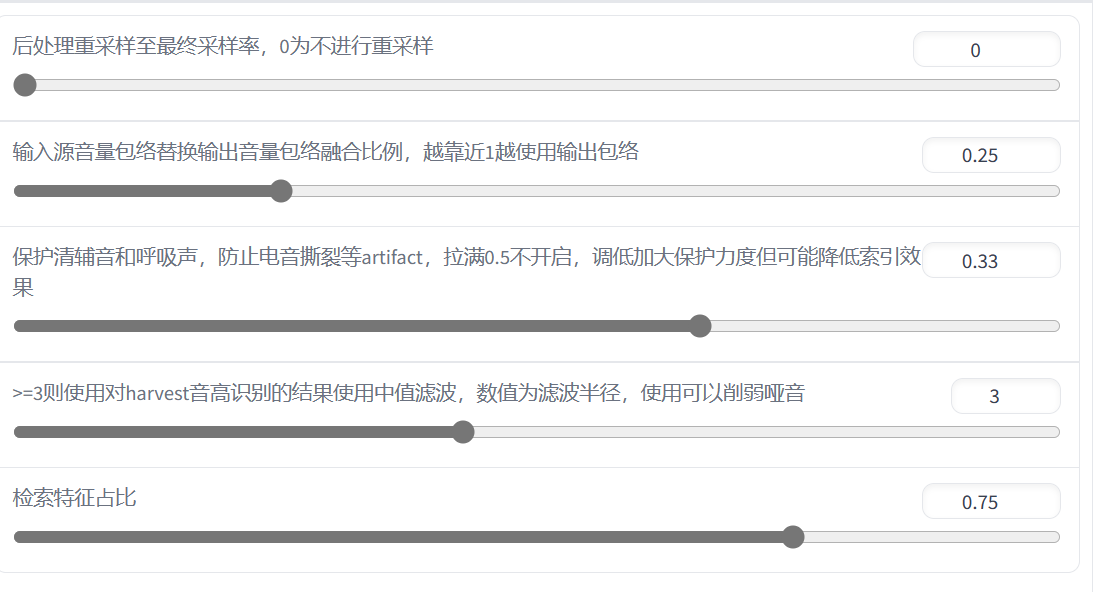
例如:对于电音撕裂,可以调小第三项来加强保护。 - 如果最终得到的人声效果不好,除了上面更改推理属性外,还可以检查一下数据集是否纯净,或者是调整训练过程的参数重新训练得到新模型(祖传调参侠)。
ps.推理时用的人声最好纯净、无杂音、无混响、无回声等,这也是笔者使用七里香的二创而不是原唱来进行模型推理的原因(原唱人声不够干净)。 - 得到目标人声后,可以导入至audition中进行降噪、混响、调音等操作,然后与bgm组合,输出得到最终作品。
文章的最后,给大家一些tips:
- 数据集为日语,推理为日语的效果普遍要比其他语言的效果好。
- 数据集语音足够干净的话,并不需要很庞大的数据量也能训练得到效果好的模型。
- 训练阶段的batch_size不要太大,不然会爆显存。一般调整到4就行。
- 有些时候翻唱的效果不好跟模型没有关系,可能是翻唱歌曲的人声部分不够清晰、干净。
Comments NOTHING